Deliberative multi-agent large language models improve clinical reasoning in ophthalmology
March 22, 2026·,,,,,,,,,,,,·
0 min read
Ehsan Misaghi
Sean T. Berkowitz
Bing Yu Chen
Qingyu Chen
Renaud Duval
Pearse A. Keane
Danny A. Mammo
Ariel Yuhan Ong
Mertcan Sevgi
Sumit Sharma
Sunil K. Srivastava
Yih Chung Tham
Fares Antaki
Abstract
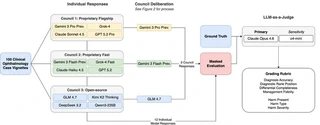
Multi-agent LLM councils were evaluated against individual language models for ophthalmology clinical reasoning across 100 clinical vignettes. Councils consistently improved accuracy across all model categories (flagship models: 95.0% vs 90.8%; fast proprietary: 96.0% vs 86.5%; open-source: 91.0% vs 83.2%) while significantly reducing harm rates. The councils produced more complete differential diagnoses and management plans through structured deliberation among models that ranked one another’s responses.
Type
Publication
arXiv